

Data analysis
Sentiment Analysis Στο Twitter: Αλέξης Τσίπρας

Sentiment Analysis Στο Twitter: Αλέξης Τσίπρας
Σε μια καφετέρια στην Πάτρα εξελισσόταν μια αρκετά ενδιαφέρουσα αλλά έντονη πολιτική συζήτηση και κάποια στιγμή έπεσε στο τραπέζι η εξής φράση:
“Ότι και να λέτε, ο κόσμος δεν δείχνει να είναι δυσαρεστημένος με τον Τσίπρα.”
Δεν ήθελε και πολύ έπειτα από αυτήν την φράση για να γίνει ακόμη πιο έντονος ο διάλογος και για να είμαστε ακριβείς πως δεν παίξανε και μπουνιές. Η όλη αυτή φάση με έκανε να αντιληφθώ και να κατανοήσω ακόμη πιο πολύ την σημαντικότητα της πολιτικής σκηνής στην καθημερινότητα του μέσου Έλληνα καθώς επίσης να με κάνει να αναρωτιέμαι το πως μπορεί να προκύπτουν τέτοιες φράσεις και που μπορεί να στηρίζονται. Έτσι, αποφάσισα να κάνω έρευνα και να ανακαλύψω κάποιες απόψεις – πάντα κατά προσέγγιση – σε ένα συγκεκριμένο δείγμα ανθρώπων που χρησιμοποιούν στην καθημερινότητα τους στα Social Media και συγκεκριμένα:
- Θα αξιοποιήσουμε το Twitter ως μέσον έρευνας μέσω της γλώσσας Python και με τα modules: Tweepy, Pandas
- Θα κάνουμε βασικές στατιστικές καθώς και σχεδιαγράμματα με τα modules: Numpy, Matplotlib, Seaborn
- Θα κάνουμε ανάλυση των δεδομένων που πήραμε από το Twitter για το πρόσωπο “Αλέξιος Τσίπρας” με το module: TextBlob
Το αποτέλεσμα που θα λάβουμε δεν θα είναι αντιπροσωπευτικό για όλους τους Έλληνες και τον γεωγραφικό προσδιορισμό “Ελλάδα”. Θα αφορά μονάχα ένα μέρος του συνόλου του Digital Engagement (Στην περίπτωση μας Twitter). Είναι όμως απόλυτο, πράγμα που σημαίνει πως υπάρχει επιστημονική προσέγγιση και πως αν κάνουμε το ίδιο και για τα άλλα Digital Engagement μέσα (π.χ Facebook, Insta) τότε θα έχουμε “Την απόφαση όλων των χρηστών του Internet”. Δεν έχω επιστημονικά δεδομένα ώστε να γνωρίζω τι πληθυσμιακή κάλυψη μπορεί να έχουν όλοι οι χρήστες του Internet στην Ελλάδα και σε τι ποσοστό αναλογούν βάση του συνολικού πληθυσμού, αλλά ένα άρθρο που θα δείτε εδώ στην Καθημερινή ισχυρίζεται πως το 50% των Ελλήνων χρησιμοποιούν τα Social Media και 55.2% έχουν εγγεγραμμένο λογαριασμό.
Αν ισχύει κάτι τέτοιο και μόνο “Άν”, τότε όπως και σε όλες τις Ευρωπαϊκές χώρες αλλά και στην Αμερική, έτσι και εδώ το Digital κομμάτι πλέον θα πρέπει να θεωρείτε αναπόσπαστο κομμάτι ανάλυσης της κοινωνικής συμπεριφοράς αφού ο μισός πληθυσμός της Ελλάδος εκφράζεται μέσω Internet. Άρα αυτός ο μισός πληθυσμός μπορεί και “ελέγχει” με τις αποφάσεις του την ίδια την χώρα και άρα δυστυχώς μπορεί και να χαλιναγωγηθεί. Αυτό όμως είναι ένα θέμα συζήτησης για άλλο post.
Σημαντικό να αναφέρουμε πριν ξεκινήσουμε ότι η διαδικασία της ανάλυσης συναισθημάτων δεν είχε ως σκοπό τέτοια post την στιγμή της γέννησης της. Γεννήθηκε από marketeers και digital marketing strategists ως ένα μέσο για να ελέγχουν το κατά πόσο οι κινήσεις τους στα Social Media έχουν θετική απήχηση ώστε να γίνουν καλύτεροι και για να χαράζουν online στρατηγικές. Για αυτό τον λόγο, παραθέτω μαζί με το post τα scripts για να μπορεί ο καθένας να κάνει την δουλειά του σε οποιοδήποτε κλάδο και αν βρίσκεται!
Προαπαιτούμενα
Πρώτα από όλα για να τρέξει κάποιος τα scripts που δίνω θα πρέπει να έχει εγκαταστήσει την γλώσσα προγραμματισμού Python. Ένας marketeer όμως δεν είναι αναγκασμένος να γνωρίζει κάποια γλώσσα προγραμματισμού για να έχει πρόσβαση σε αυτές τις λειτουργίες, για αυτό και προτείνω να κατεβάσετε το Anaconda που εμπεριέχει μέσα την γλώσσα Python καθώς και τα “Jupyter Notebooks” (τα σημειωματάρια) στα οποία μπορείς να κάνεις επικόλληση τα scripts που δίνω. Άρα δεν χρειάζεται να καταλαβαίνεις τον κώδικα για να έχεις το ίδιο αποτέλεσμα που θα διαβάσεις παρακάτω – για κάποια δική σου δουλειά.
Αφού κάνουμε εγκατάσταση το Anaconda, ανοίγουμε το “Jupyter Notebook” όπως ανοίγει ο καθένας οποιοδήποτε πρόγραμμα κάνει εγκατάσταση στον υπολογιστή του. Εκεί, θα πρέπει να κάνουμε εγκατάσταση τα προαναφερθέντα modules προκειμένου ο κώδικας μας να λειτουργήσει σωστά. Τα Modules είναι τα εξής:
- Numpy
- Pandas
- Tweepy
- Matplotlib
- Seaborn
- Textblob
Για να τα κάνουμε εγκατάσταση, γράφουμε:
!pip install numpy pandas tweepy matplotlib seaborn textblobΌπως φαίνεται στην από κάτω εικόνα και πατάμε cntrl + Enter. Θα ξεκινήσει η εγκατάσταση και είμαστε έτοιμοι!

![]()
1. Εξαγωγή των Δεδομένων από το Twitter
1.1 Εισαγωγή των βιβλιοθηκών (Modules)
Είναι τόσο εύκολο, όσο φαίνεται στην από κάτω εικόνα – Αντιγραφή επικόλληση.
# Γενικά Modules:
import tweepy # Για την διασύνδεση με Twitter API
import pandas as pd # Για τα Δεδομένα
import numpy as np # Για αριθμητικές/στατιστικές πράξεις
# Για διαγράμματα & σχεδιαγράμματα:
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineΤέλεια! Πατάμε cntrl+Enter στο Jupyter και πάμε στο επόμενο!
1.2 Δημιουργία ενός Twitter App
Για να μπορέσουμε να εξάγουμε τα Tweets για ανάλυση χρειαζόμαστε πρόσβαση σε έναν λογαριασμό Twitter καθώς επίσης να δημιουργήσουμε ένα Twitter app. Αυτό γίνεται πανεύκολα αν πάμε εδώ https://apps.twitter.com. Πατάμε Create New App, Συμπληρώνουμε τα απαραίτητα στοιχεία και είμαστε έτοιμοι. Από αυτό το twitter app εμείς χρειαζόμαστε τα εξής στοιχεία:
- Consumer Key (API Key)
- Consumer Secret (API Secret)
- Access Token
- Access Token Secret
Ακολουθεί ένα παράδειγμα του Script:
# Twitter App access keys
# Consume:
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
# Access:
ACCESS_TOKEN = ''
ACCESS_SECRET = ''Θα πάρετε αυτό το script και θα το βάλετε σε ένα αρχείο .txt και θα αντικαταστήσετε τα δεδομένα που σας δίνω με τα δεδομένα του λογαριασμού σας του Twitter. Έπειτα, αφού το κάνετε αυτό, θα το μετονομάσετε σε “credentials.py” και θα το κάνετε Upload μέσα στο Jupyter Notebook από το κουμπάκι που λέει “Upload”. Είναι τόσο απλό όσο ακούγεται. Ο λόγος που διαχωρίζω το αρχείο αυτό σε σχέση με τον υπόλοιπο κώδικα είναι επειδή χρειαζόμαστε μόνο τα values για αυτά τα variables και τίποτα άλλο.Τώρα που έχουμε διασύνδεση με το API θέλουμε να φτιάξουμε μια λειτουργία η αλλιώς καλύτερα όπως το λέμε στην Python ένα “Function”. Θα το φτιάξω σε άλλο κελί με κώδικα στο Jupyter για να έχω σε τμήματα τον κώδικα, ώστε αν κάνω λάθη η θέλω αλλαγές να μην δυσκολεύομαι και θα το τρέξω:
# Κάνουμε Import τα access keys:
from credentials import * # Αυτό θα μας επιτρέψει να
#χρησιμοποιήσουμε τα keys ως variables
# API's setup:
def twitter_setup():
"""
Setup του Twitter's API
με τα κλειδιά μας.
"""
# Authentication & access using keys:
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Return API with authentication:
api = tweepy.API(auth)
return apiΜέχρις ώρας όλα καλά! Σωστά; Τώρα είμαστε έτοιμοι να κάνουμε εξαγωγή τα tweets.
1.3 Εξαγωγή των Tweets
Τώρα που φτιάξαμε το function για το Twιtter API, μπορούμε να το χρησιμοποιήσουμε για να δημιουργήσουμε έναν “εξαγωγέα” που θα το ονομάσουμε “extractor” και θα είναι object. Μετά από αυτό, θα χρησιμοποιήσουμε την λειτουργία του module Tweepy από ένα συγκεκριμένο “twitter name” την ποσότητα και τον αριθμό των tweets.
Όπως αναγράφεται και στον τίτλο, επέλεξα τον @atsipras σαν τον χρήστη που θα κάνω εξαγωγή τα δεδομένα. Και για όσους δεν γνωρίζουν και μπορεί να τους φάει η περιέργεια, ΝΑΙ είναι 100% νόμιμο, με νόμιμα μέσα και με API που διαθέτει το ίδιο το twitter (ειδάλλως δεν θα το διέθετε και θα ήταν παράνομο).
# Ο τρόπος για να κάνουμε Extract τα Twitter Data:
# Και φτιάχνουμε το object "extrator"
extractor = twitter_setup()
# Δημιουργούμε την λίστσα με τα tweets :
tweets = extractor.user_timeline(screen_name="atsipras", count=500)
print("Number of tweets extracted: {}.\n".format(len(tweets)))
# Εκτυπώνουμε τα 5 πιο πρόσφατα tweets:
print("5 recent tweets:\n")
for tweet in tweets[:5]:
print(tweet.text)
print()Με τον παραπάνω κώδικα, θα έχουμε ένα αποτέλεσμα όπως φαίνεται παρακάτω (και θα μπορούμε να το ελέγξουμε live με τον λογαριασμό του twitter για να δούμε αν είμαστε σωστοί)
Number of tweets extracted: 200. 5 recent tweets: H πρόταση για την παραπομπή τριών υπουργών της κυβέρνησης για το σκάνδαλο του φαρμάκου, αποτελεί μια κακοστημένη απ… https://t.co/xaxSfH7gnh RT @PrimeministerGR: #LIVE: Ομιλία στη #Βουλή στη συζήτηση επί της πρότασης που κατέθεσαν ο Αρχηγός της Αξιωματικής Αντιπολίτευσης και 73 Β… Με την οξυδέρκεια και τη σοφία του, με τη καυστική του πένα και τις ιδέες του, έπαιξε καθοριστικό ρόλο στο να γίνει… https://t.co/N9QrEyefhJ Είναι δύσκολο να αποχαιρετάς έναν δικό σου άνθρωπο. Ο Βασίλης ήταν δίπλα μας όλα τα χρόνια της αναγέννησης και της ανόδου του ΣΥΡΙΖΑ. Επικοινώνησα σήμερα με τον Όλ.Σολτζ να του ευχηθώ κάθε επιτυχία στα νέα του καθήκοντα. Ελπίζουμε ότι η δύσκολη αυτή… https://t.co/q6mC631kw2
Τώρα έχουμε και έναν εξαγωγέα αλλά και τα δεδομένα που εξάγαμε από το Twitter.
Δημιουργία ενός DataFrame
1.4 Δημιουργώντας ένα (pandas) DataFrame
Τι είναι ένα pandas dataframe; Στην ουσία είναι ένας τρόπος να “παίξουμε” και να παρουσιάσουμε τα δεδομένα. Υπάρχουν κάποια functions που μας επιτρέπουν να τραβήξουμε δεδομένα με μια εντολή μονάχα όπως π.χ το head(). Έτσι εγώ θα τραβήξω αυτήν την φορά 10 tweets (αντί για 5 που τράβηξα πιο πάνω) με τον παρακάτω κώδικα:
# Έτσι δημιουργούμαι ένα dataframe:
data = pd.DataFrame(data=[tweet.text for tweet in tweets], columns=['Tweets'])
# Κάνουμε display τα 10 πρώτα:
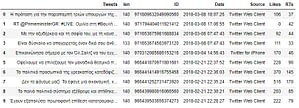
display(data.head(10))Και θα έχουμε το εξής αποτέλεσμα:
Tweets
0 H πρόταση για την παραπομπή τριών υπουργών της...
1 RT @PrimeministerGR: #LIVE: Ομιλία στη #Βουλή ...
2 Με την οξυδέρκεια και τη σοφία του, με τη καυσ...
3 Είναι δύσκολο να αποχαιρετάς έναν δικό σου άνθ...
4 Επικοινώνησα σήμερα με τον Όλ.Σολτζ να του ευχ...
5 Οφείλουμε να επιλέξουμε τον μοναδικό θεσμικά π...
6 Το πολιτικό προσωπικό της χρεοκοπίας κατεδάφιζ...
7 Δεν τα φάγαμε μαζί. Τα έφαγε μια οικονομική, κ...
8 Το παλιό πολιτικό σύστημα εξέθρεψε και στήθηκε...
9 Έχουν εξαπολύσει πρωτοφανή επίθεση κατατρομοκρ...Και έτσι, έχουμε ένα ωραίο τραπέζι με όμορφα και κατηγοριοποιημένα δεδομένα.
Τώρα, αν υπάρχει κάτι εντυπωσιακό από όλη αυτήν την υπόθεση, είναι οι “μέθοδοι” που μπορούμε να τραβήξουμε τα δεδομένα. Είναι πολύ δύσκολο σε κάποιον που δεν γνωρίζει προγραμματισμό να καταλάβει τι ακριβώς κάνει “μια μέθοδος” αλλά ας πούμε το ζουμί είναι οι “extra” δυνατότητες που μας δίνονται. Σε αυτήν την περίπτωση συγκεκριμένα το module “Twepy” μας δίνει τις εξής μεθόδους:
# Εσωτερικοί μέθοδοι από 1 απλό tweet:
print(dir(tweets[0]))Αυτή η εντολή μας δίνει αυτά τα στοιχεία
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__',
'__getstate__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '__weakref__', '_api', '_json',
'author', 'contributors', 'coordinates', 'created_at',
'destroy', 'entities', 'favorite', 'favorite_count',
'favorited', 'geo', 'id', 'id_str', 'in_reply_to_screen_name',
'in_reply_to_status_id', 'in_reply_to_status_id_str'
, 'in_reply_to_user_id', 'in_reply_to_user_id_str',
'is_quote_status', 'lang', 'parse', 'parse_list',
'place', 'possibly_sensitive', 'retweet', 'retweet_count',
'retweeted', 'retweets', 'source', 'source_url',
'text', 'truncated', 'user']Που αν προσπαθήσουμε έστω και λίγο να τα διαβάσουμε θα καταλάβουμε κάποια από αυτά. Παράδειγμα “author”, “contributors”, “created_at”, “geo”, “id”. Γενικώς οι μέθοδοι είναι πολύ χρήσιμες διότι μας βοηθούν να καταλάβουμε κάποια βασικά στοιχεία όπως το Spam, τα ψεύτικα σχόλια, τα bots, και οτιδήποτε πάει να πειράξει την ποιότητα των δεδομένων μας (στην συγκεκριμένη περίπτωση όχι παντού ή πάντα).
Ας δοκιμάσουμε να πάρουμε κάποιες πληροφορίες από το 1ο Tweet.
# Πληροφορίες από το 1ο tweet:
print(tweets[0].id)
print(tweets[0].created_at)
print(tweets[0].source)
print(tweets[0].favorite_count)
print(tweets[0].retweet_count)
print(tweets[0].geo)
print(tweets[0].coordinates)
print(tweets[0].entities)Θα πάρουμε κάτι τέτοιο ως αποτέλεσμα
971809632049090560
2018-03-08 18:07:26
Twitter Web Client
106
37
None
None
{'hashtags': [], 'symbols': [], 'user_mentions': [],
'urls': [{'url': 'https://t.co/xaxSfH7gnh',
'expanded_url': 'https://twitter.com/i/web/status/971809632049090560',
'display_url': 'twitter.com/i/web/status/9…', 'indices': [117, 140]}]}Και τώρα είμαστε σε θέση να τα βάλουμε σε μια τάξη και να τα χώσουμε όλα μέσα σε ένα DataFrame.
1.5 Προσθέτοντας Στοιχεία στο DataFrame
Όπως μπορέσαμε να δούμε παραπάνω, μπορούμε να τραβήξουμε αρκετές πληροφορίες και δεδομένα από ένα απλό tweet. Όμως, όλα αυτά τα δεδομένα δεν είναι πάντα χρήσιμα. Κάθε ανάλυση χρειάζεται συγκεκριμένα δεδομένα που να ταιριάζουν στον σκοπό της και εμείς στο δικό μας dataframe θα προσθέσουμε μερικά δεδομένα από αυτά. Για αυτό, θα αξιοποιήσουμε ταυτοχρόνως τις λίστες της Python για να δημιουργήσουμε νέες στήλες πολύ απλά προσθέτοντας μια ονομασία ανάμεσα στα αποσιωπητικά. Άρα θα έχουμε το εξής:
# Βάζουμε δεδομένα που μας ενδιαφέρουν:
data['len'] = np.array([len(tweet.text) for tweet in tweets])
data['ID'] = np.array([tweet.id for tweet in tweets])
data['Date'] = np.array([tweet.created_at for tweet in tweets])
data['Source'] = np.array([tweet.source for tweet in tweets])
data['Likes'] = np.array([tweet.favorite_count for tweet in tweets])
data['RTs'] = np.array([tweet.retweet_count for tweet in tweets])Και για να δούμε τα πρώτα 10 αποτελέσματα
# Display of first 10 elements from dataframe: display(data.head(10))
Τώρα που προετοιμάσαμε τα δεδομένα μας και είναι σε μια μορφή που είναι εύκολα προσβάσιμα, ήρθε η ώρα να τα “στρώσουμε” λίγο, να μαζέψουμε κάποια στατιστικά δεδομένα και να φτιάξουμε κάποια σχεδιαγράμματα που θα μας κάνουν να καταλάβουμε τι ακριβώς γίνεται.
2. Visualization & Βασική Στατιστική
2.1 Μέση Τιμή & Δημοτικότητα
Θέλουμε να υπολογίσουμε κάποια στατιστικά δεδομένα όπως τον μέσο όρο του μήκους όλων των tweets, τα tweets με τα περισσότερα likes, αντίστοιχα με τα λιγότερα, τα retweets κλπ. Για να το κάνω αυτό χρησιμοποιώ numeric Python (numpy).
# Εξαγωγή μέσου όρου μήκους:
mean = np.mean(data['len'])
print("Ο Μέσος Όρος του μήκους κάθε Tweet: {}".format(mean))Ο Μέσος Όρος του μήκους κάθε Tweet: 134.98Για να εξάγουμε περισσότερα δεδομένα, θα βάλουμε πάλι Pandas:
# Εξαγωγή Tweet με περισσότερα Likes & RT's:
fav_max = np.max(data['Likes'])
rt_max = np.max(data['RTs'])
fav = data[data.Likes == fav_max].index[0]
rt = data[data.RTs == rt_max].index[0]
# Max FAVs:
print("Το Tweet με τα πιο πολλά like είναι: \n{}".format(data['Tweets'][fav]))
print("Αριθμός των likes: {}".format(fav_max))
print("{} characters.\n".format(data['len'][fav]))
# Max RTs:
print("Το tweet με τα περισσότερα retweets: \n{}".format(data['Tweets'][rt]))
print("Αριθμός των retweets: {}".format(rt_max))
print("{} characters.\n".format(data['len'][rt]))Και παίρνουμε το εξής αποτέλεσμα:
Το tweet με τα πιο πολλά like είναι:
10/2/2008.
Συνεχίζουμε με το ίδιο πάθος, τον ίδιο ενθουσιασμό, την ίδια (ίσως και λίγο παραπάνω) τόλμη...
Αν και μ… https://t.co/LEL245QANC
Αριθμός των likes: 654
140 characters.
Το tweet με τα περισσότερα retweets:
Δεν τα φάγαμε μαζί. Τα έφαγε μια οικονομική, κοινωνική-πολιτική ελίτ που έστησε επί δεκαετίες τα δίκτυα της εξουσία… https://t.co/lmzwbVZgXz
Αριθμός των retweets: 170
140 characters.
Την στιγμή που έλαβα αυτά τα αποτελέσματα ήμουν έτοιμος να πάθω εγκεφαλικό. Τα πιο πολλά likes τα έχει ένα tweet από το 2008. Ήταν τότε εκείνη η εποχή που δεν είχε έρθει ακόμη η ελπίδα. Είναι κατανοητό.
Όμως, το tweet με τα περισσότερα retweets είναι η πρόσφατη ανακοίνωση του σκανδάλου της Novartis. Δηλαδή από τα τόσα χρόνια παρουσίας του λογαριασμού του twitter, και από όσα έχουν περάσει και έχουν συζητηθεί σε καθημερινή βάση είτε σε τηλεοράσεις, είτε σε ραδιόφωνα είτε στο internet, το tweet εκείνο που “μοίρασε ο κόσμος” ήταν αυτό. Ο κόσμος ΔΕΝ μοίρασε tweets που έχουν να κάνουν με την Εθνική ασφάλεια της χώρας μας π.χ με τα καθημερινά δεδομένα με την Τουρκία, με τους στρατιωτικούς που πιάσανε, με τα μνημόνια αλλά…. με την εκδίκηση.
Spoiler Alert και να με συγχωρείτε, αλλά το retweet αυτό το έκανε και κόσμος που “βρίζει” τακτικά τον Σύριζα σε κάθε post που γίνεται αλλά από ότι φαίνεται η εκδίκηση του Έλληνα δεν έχει χρώμα ούτε διαλέγει γωνίες (αριστερές η δεξιές) – μόνο στην εκδίκηση βέβαια. Για την ακρίβεια ο Έλληνας προτιμάει από ότι φαίνεται να συντηρήσει μια κατάσταση και να τιμωρηθούν κάποιοι, παρά να δει την κατάσταση ως έχει για ένα καλύτερο αύριο.
Ο Έλληνας ζητάει τιμωρίες. Ίσως πάει τιμωρία και ψήφος
Ας προχωρήσουμε παρακάτω στην ανάλυση και να μην μείνουμε εδώ. Εξάλλου νομίζω ότι δεν σας λέω και κάτι καινούργιο πέρα από την επιστημονική τεκμηρίωση της άποψης αυτής. Ας πάμε στα σχεδιαγράμματα.
2.2 Σχεδιαγράμματα με Time-Series
Καταρχήν γιατί Time-Series; Πολύ απλά για να δούμε με το πέρας του χρόνου την απήχηση του λογαριασμού. Τα pandas, έχουν δικά τους time-series και γίνονται πολύ εύκολα, οπότε:
# Δημιουργούμε time-series για τα δεδομένα:
tlen = pd.Series(data=data['len'].values, index=data['Date'])
tfav = pd.Series(data=data['Likes'].values, index=data['Date'])
tret = pd.Series(data=data['RTs'].values, index=data['Date'])Και για να τα εμφανίσουμε σε διάγραμμα:
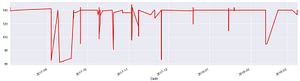
# Μήκη με βάση τον χρόνο: tlen.plot(figsize=(16,4), color='r');
Αν εξαιρέσουμε τον 9ο και 10ο μήνα του 2017 όπου φαίνεται μια “απουσία”, τους άλλους μήνες βλέπουμε σταθερή παρουσία στα Social Media. Μπράβο Αλέξη, είσαι ενεργός χρήστης!
Ας κάνουμε τώρα ένα σχεδιάγραμμα και να δούμε τα like σε σχέση με τα retweets!
# Likes vs retweets visualization: tfav.plot(figsize=(16,4), label="Likes", legend=True) tret.plot(figsize=(16,4), label="Retweets", legend=True);
Όπως θα παρατηρήσουμε στο από πάνω σχεδιάγραμμα, όντως στα μέσα του 2ου μήνα του 2018, τότε με το σκάνδαλο Novartis, έπεσε πολύ like. Άρα θα μπορούσε να πει κανείς πως υπάρχει μια σχέση – ένα corellation μεταξύ likes και retweets.
2.3 Pie Charts από τις πηγές
Θα σχεδιάσουμε μια “πίτα” με τις πηγές από όπου προήλθαν τα tweets. Αυτό μας βοηθάει να καταλάβουμε αλλά και να αναλύσουμε περαιτέρω SPAM, Junk Traffic, και παίρνουμε πληροφορίες για οτιδήποτε χρειαζόμαστε. Ας καθαρίσουμε πρώτα τις πηγές.
# Πρώτα μαζεύουμε τις πηγές:
sources = []
for source in data['Source']:
if source not in sources:
sources.append(source)
# Εκτυπώνουμε τις πηγές:
print("Πηγές Δημιουργίας Περιεχομένου:")
for source in sources:
print("* {}".format(source))Πηγές Δημιουργίας Περιεχομένου:
* Twitter Web Client
* Twitter for iPhone
* Twitter for Android
* TweetDeckΌπως θα παρατηρήσουμε, οι χρήστες που ήταν ενεργοί στα tweets, retweets, στα σχόλια αξιοποίησαν το twitter μέσω Web Browser, Iphone, Android, και…. TweetDeck! Κάποιοι φανατισμένοι είναι συνέχεια μέσα. Μήπως είναι και marketeers;; 😀
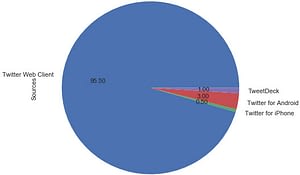
Τώρα θα μετρήσουμε ξεχωριστά την κάθε πηγή και θα φτιάξουμε ένα pie chart:
# Φτιάχνουμε numpy vector με labels: percent = np.zeros(len(sources)) for source in data['Source']: for index in range(len(sources)): if source == sources[index]: percent[index] += 1 pass percent /= 100 # Pie chart: pie_chart = pd.Series(percent, index=sources, name='Sources') pie_chart.plot.pie(fontsize=11, autopct='%.2f', figsize=(6, 6));
Παραπάνω παρατηρούμε το ποσοστό των tweets με βάση την κάθε πηγή. Αν κάτι μας κάνει εντύπωση είναι ότι το ποσοστό των Tweets μέσω της ιστοσελίδας του Twitter είναι 95.5%. Άρα ο κόσμος που ασχολείται κατά κύριο λόγο με το εν λόγω θέμα είναι τουλάχιστον πάνω από 28 χρονών διότι η παρουσία του mobile engagement είναι ελάχιστη.
Τώρα μπορούμε να προχωρήσουμε στην ανάλυση συναισθήματος.
3. Ανάλυση Συναισθήματος
3.1 Εισαγωγή TextBlob
Όπως αναφέραμε στην αρχή του άρθρου, θα αξιοποιήσουμε το TextBlob για να κάνουμε την ανάλυση συναισθήματος. Δυστυχώς όμως σε σχέση με τα προαναφερθέντα η λειτουργία του TextBlob δεν είναι τόσο user-friendly και αν κάποιος δεν ασχολείται με τον προγραμματισμό μπορεί να τα βλέπει δυσνόητα διότι υπάρχουν μέσα regular expressions και διάφορα άλλα. Οπότε εσείς παίρνετε αντιγραφή-επικόλληση τον κώδικα και δεν δίνετε σημασία.
from textblob import TextBlob
import re
def clean_tweet(tweet):
'''
Λειτουργία για να καθαρήσουμε το κείμενο ενός tweet
Αφαιρόντας links & special characters.
'''
return ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
def analize_sentiment(tweet):
'''
Λειτουργία για ταξινόμηση της πόληωσης ενός tweet
χρησιμοποιόντας textblob.
'''
analysis = TextBlob(clean_tweet(tweet))
if analysis.sentiment.polarity > 0:
return 1
elif analysis.sentiment.polarity == 0:
return 0
else:
return -1Για να αναλύσουμε τις λέξεις, θα πρέπει να έχουμε ένα μοντέλο που να το έχουμε “εκπαιδεύσει”. Το TextBlob έρχεται με ήδη με ένα εκπαιδευμένο δικό του μοντέλο αλλά μόνο για τις αγγλικές φράσεις και όχι για τις Ελληνικές. Θα χρησιμοποιήσω το δικό μου σε αυτήν την περίπτωση. Αν θέλετε και εσείς να φτιάξετε το δικό σας μοντέλο μπορείτε να πάρετε πληροφορίες από εδώ. Οπότε έχετε υπόψιν ότι τα αποτελέσματα που θα λάβετε θα είναι διαφορετικά από τα δικά μου σε περίπτωση που το κάνετε μόνοι σας.
Όπως και να έχει, ας δούμε τώρα τον πίνακα που λάβαμε όπου “υπάρχει αρκετό συναίσθημα για ανάλυση”.
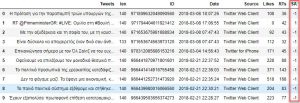
# Φτιάχνουμε μια στήλη με τα αποτελέσματα της ανάλυσης: data['SA'] = np.array([ analize_sentiment(tweet) for tweet in data['Tweets'] ]) # Προβάλουμε το ανανεωμένο dataframe με την νέα στήλη: display(data.head(10))
Όπως θα δείτε στην από πάνω εικόνα, λάβαμε για το παράδειγμα μας από τα πρώτα 10 tweets την ανάλυση του συναισθήματος (εμείς θα κάνουμε για όλα). Είναι η στήλη “SA” και το 0,1,-1 είναι οι ανάλογες βαθμίδες. Ας προχωρήσουμε στην ανάλυση των συναισθημάτων τώρα συνολικά.
3.2 Αναλύοντας τα αποτελέσματα
Τώρα θα μετρήσουμε τα tweets, θα αναλύσουμε τα ποσοστά, τα retweets, όλα τα πάντα με πολύ εύκολο τρόπο!
# Φτιάχνουμε λίστες με classified tweets:
pos_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] > 0]
neu_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] == 0]
neg_tweets = [ tweet for index, tweet in enumerate(data['Tweets']) if data['SA'][index] < 0]Ας εκτυπώσουμε τώρα τα αποτελέσματα (τα ποσοστά)
# Εκτύπωση ποσοστών:
print("Ποσοστό θετικών tweets: {}%".format(len(pos_tweets)*100/len(data['Tweets'])))
print("Ποσοστό ουδέτερων tweets: {}%".format(len(neu_tweets)*100/len(data['Tweets'])))
print("Ποσοστό αρνητικών tweets: {}%".format(len(neg_tweets)*100/len(data['Tweets'])))Και έχουμε το εξής αποτέλεσμα:
Ποσοστό θετικών tweets: 23.5%
Ποσοστό ουδέτερων tweets: 2.18%
Ποσοστό αρνητικών tweets: 74.32%Κατακλείδα
Με βάση το μέσον “Twitter” και με βάση την ανάλυση του προσωπικού λογαριασμού του πρωθυπουργού, το 74.32% του πολιτικοποιημένου twitter κόσμου δυσανασχετεί με την υπάρχουσα κυβέρνηση η με το υπάρχον πρόσωπο. Παρατηρήθηκε όμως ένα 23.5% ποσοστό το οποίο είναι μεγάλο και βλέπει θετικά αυτήν την στάση. Για να είμαστε πιο συγκεκριμένοι, αν “αφαιρέσουμε” από την ανάλυση οτιδήποτε αφορά “Τιμωρίες”, “Σκάνδαλα Novartis”, και όλα τα μισητά – το ποσοστό αρνητικών tweets ακουμπάει το 90%. Άρα φανταστείτε ότι μέσα σε 1 εβδομάδα, 15% των twitter λογαριασμών “αλλαξοπίστησε” γιατί το εκφράζει η τιμωρία αφού λογικά μπορεί και οι ίδιοι να είναι πονεμένοι (όπως όλος ο κόσμος). Αν ήμουν προσωπικός μάνατζερ του πρωθυπουργού θα του έλεγα να ασχολείται μόνο με τιμωρίες και σκάνδαλα για να κερδίσει τις επόμενες εκλογές. Ο Έλληνας με βάση την ανάλυση φαίνεται ανακυκλώσιμο προϊόν που αν μπορεί να κατηγορήσει κάποιον – θα το κάνει.
Για όσους θέλουν να μάθουν περισσότερα πράγματα με τους παραπάνω κώδικες, τα libaries και ότι έχει χρησιμοποιηθεί, σας δίνω διάφορες πηγές.
Πηγές
1. Official Documentation – Tweepy
2. Official Documentation – Numpy
3. Official Documentation – Pandas
4. Official Documentation – Matplotlib
Δημοσίευση σχολίου
Παρακαλώ το σχόλιο σας να είναι σχετικό με την παραπάνω ανάρτηση